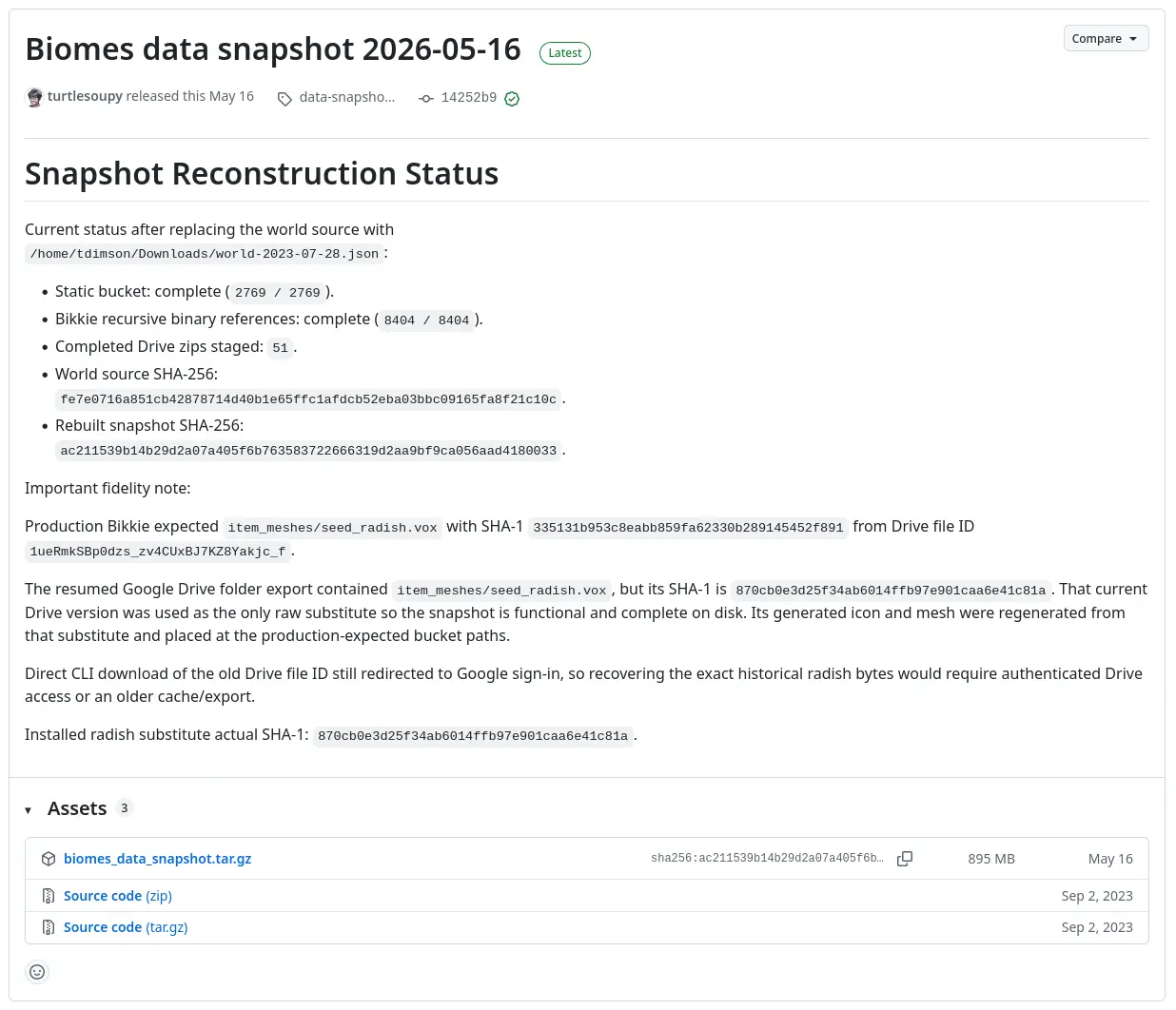
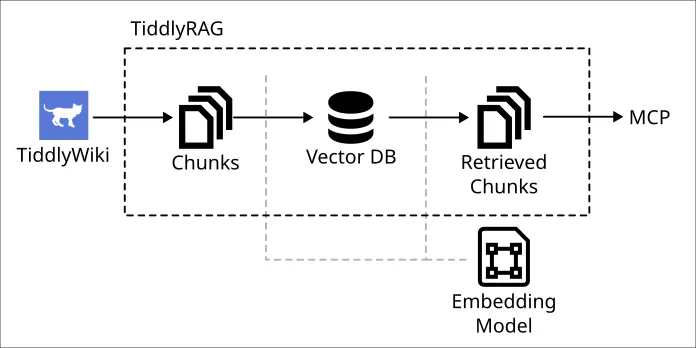
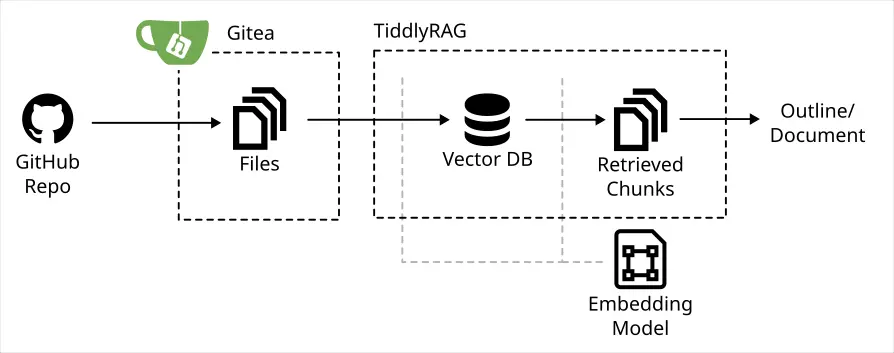
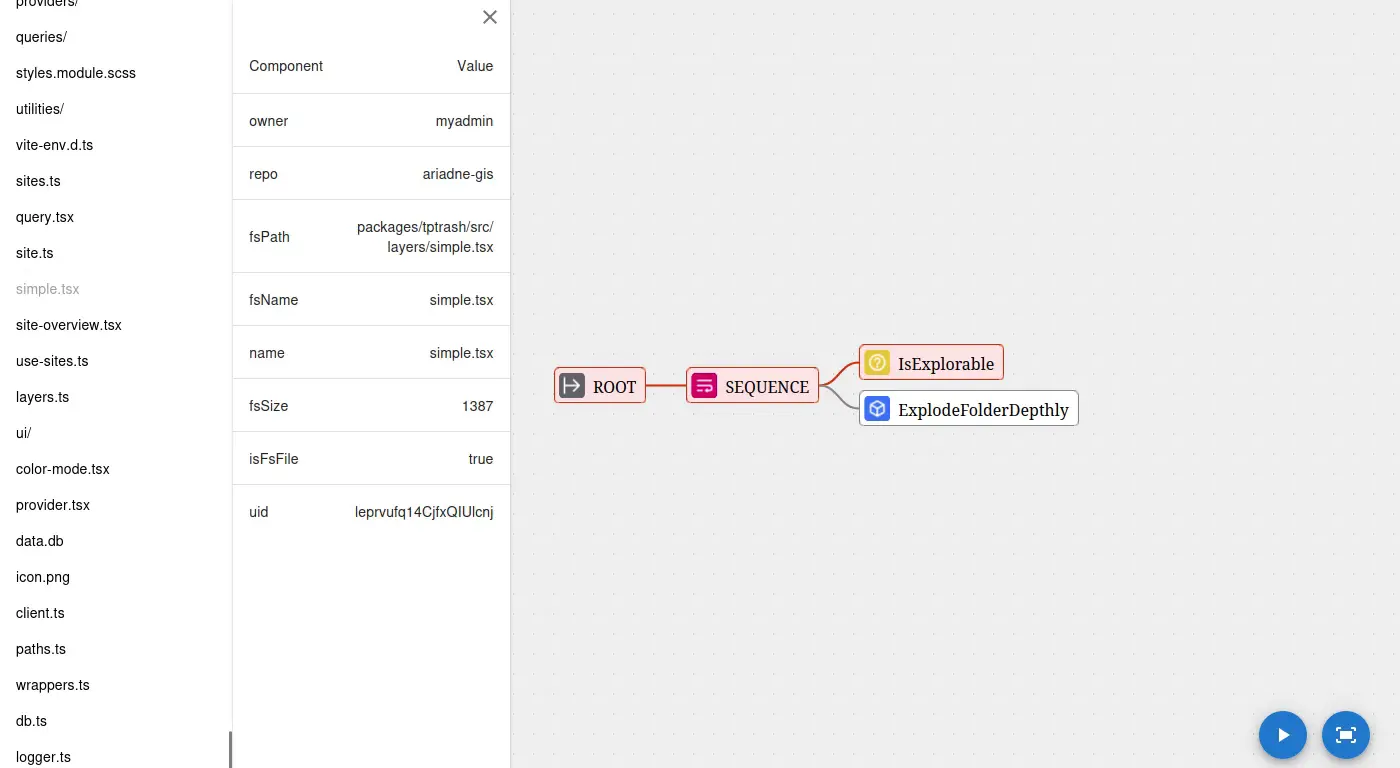
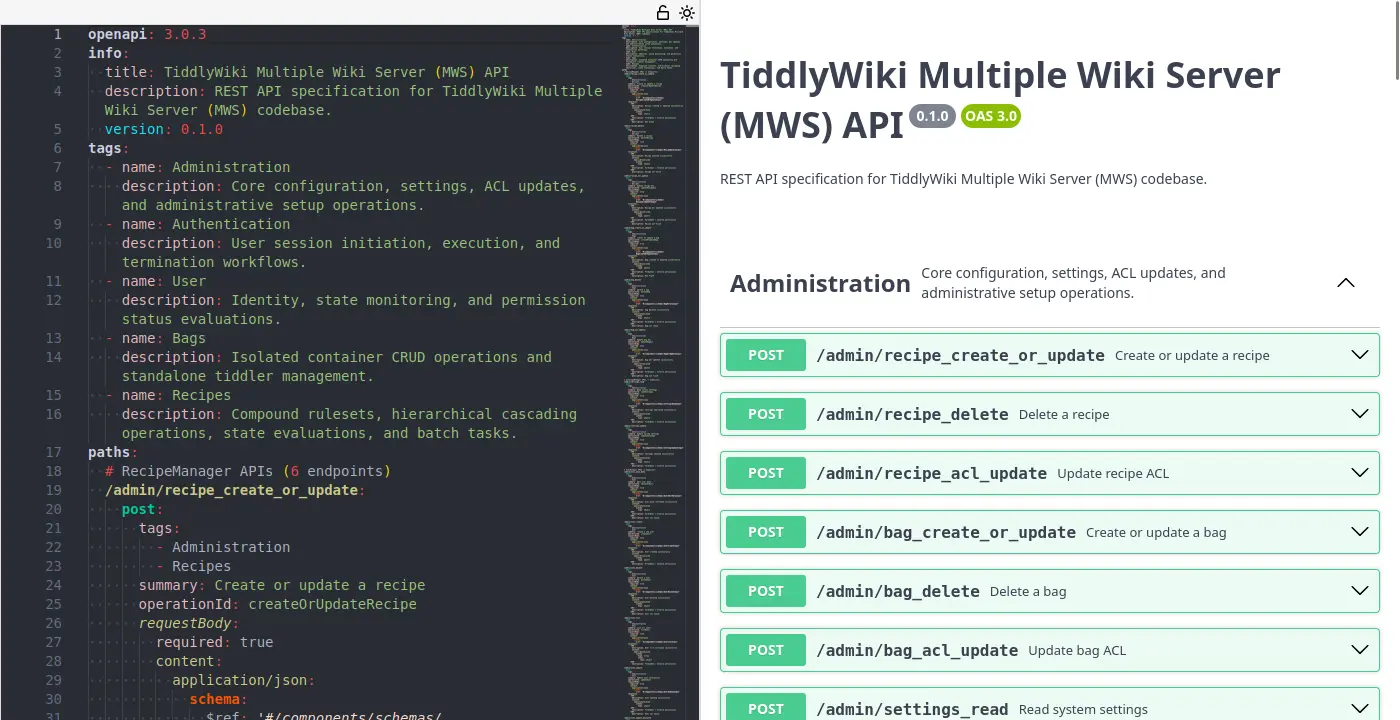
[ocr] | srv params_from_: Chat format: peg-native
[ocr] | slot get_availabl: id 3 | task -1 | selected slot by LRU, t_last = -1
[ocr] | slot launch_slot_: id 3 | task -1 | sampler chain: logits -> ?penalties -> ?dry -> ?top-n-sigma -> top-k -> ?typical -> top-p -> min-p -> ?xtc -> temp-ext -> dist
[ocr] | slot launch_slot_: id 3 | task 0 | processing task, is_child = 0
[ocr] | slot update_slots: id 3 | task 0 | new prompt, n_ctx_slot = 4096, n_keep = 0, task.n_tokens = 1179
[ocr] | slot update_slots: id 3 | task 0 | n_tokens = 0, memory_seq_rm [0, end)
[ocr] | slot update_slots: id 3 | task 0 | prompt processing progress, n_tokens = 5, batch.n_tokens = 5, progress = 0.004241
[ocr] | slot update_slots: id 3 | task 0 | n_tokens = 5, memory_seq_rm [5, end)
[ocr] | srv process_chun: processing image...
[ocr] | encoding image slice...
[ocr] | image slice encoded in 21944 ms
[ocr] | decoding image batch 1/5, n_tokens_batch = 256
[ocr] | image decoded (batch 1/5) in 197 ms
[ocr] | decoding image batch 2/5, n_tokens_batch = 256
[ocr] | image decoded (batch 2/5) in 576 ms
[ocr] | decoding image batch 3/5, n_tokens_batch = 256
[ocr] | image decoded (batch 3/5) in 335 ms
[ocr] | decoding image batch 4/5, n_tokens_batch = 256
[ocr] | image decoded (batch 4/5) in 412 ms
[ocr] | decoding image batch 5/5, n_tokens_batch = 142
[ocr] | image decoded (batch 5/5) in 428 ms
[ocr] | srv process_chun: image processed in 23892 ms
[ocr] | slot init_sampler: id 3 | task 0 | init sampler, took 0.01 ms, tokens: text = 13, total = 1179
[ocr] | slot update_slots: id 3 | task 0 | prompt processing done, n_tokens = 1179, batch.n_tokens = 8
[ocr] | slot print_timing: id 3 | task 0 |
[ocr] | prompt eval time = 24747.40 ms / 1179 tokens ( 20.99 ms per token, 47.64 tokens per second)
[ocr] | eval time = 93429.63 ms / 2917 tokens ( 32.03 ms per token, 31.22 tokens per second)
[ocr] | total time = 118177.03 ms / 4096 tokens
[ocr] | slot release: id 3 | task 0 | stop processing: n_tokens = 4095, truncated = 1
[ocr] | srv update_slots: all slots are idle
[ocr] | srv stop: cancel task, id_task = 0
[ocr] | srv update_slots: all slots are idle
[ocr] | srv operator(): got exception: {"error":{"code":500,"message":"Failed to parse input at pos 0: TQ;的既然既然 既然既然 称即作四作作作�는戒инин 교 교浦に��집집집 அமை作 (ӀэӀэӀэӀэ的的��ده层透明透明ண்டுண்டு羡羡 the the\n\n\n裔5�(,,,�輒放放��貲支����ver.جی顯顯由於宇丁ine 的有เพ阵年是 ilesuணணஸஸ�興�����。那那那ӀэӀэӀэ蚚��图的疾 ..,то角角���ололол���浆â�,,,的的��,,,,的的�,,場从shshdd�,0,,贺的的的的的的\n\n的的200,,,,,,禹.\nmff..,只有在y���转 .,,,争www-----�� iew徒��\n\n\n\n\nimetையில்ையில்ையில்ையில்友ssss ,,,,,,,,,的的���,,的 war and and and and andsw81生\n({{\\市ne季季食生生生生�清清��在在评ans芽lan\n\n\n\n ���,,,的的的��,,,,,���,,,,,�����-,((���ek of 的的的���,,,00,,,的的的失失失���,,的的的���,,,,,的��,,,99 简称oofCCèге�顯顯韓韓韓韓韓友���的\n�夫夫��与非与非与非与非————��ataadyofofofofof涓,,,niluoppnnnn..,,,,���,,,的的成,ansuu�,,,,,,��,,,\n00ofn�.,,,,ிறிறிறிறிற\n1ไ\n\n\n\n\n\n r.�,,,评\n\n\nbu-..-.-首位ofuns党 from\n评gg\n\n\nss\n\n\n\n\n W I I \n\n\n \n,.\n\n in in in in in in in in in e sl el�� \n\n\n1 ไ\n�.,,,,的��否o�----08��,,\n\n\n\n\n\n1情 \n 妇\n�,,,,,,��,,, or 1 and and and and\n\n\nlot\nر \n\n\n۹ \n\n\n\n\n\n,,,的���,,,,回归--..,\n\n\n �,,,的的的�蛛��-- in in\n\n fa以下的 \n ofans\n F F E E E E连连连新新 F的的的的的的的的 W Group\\.��âè以下的以下的以下的以下的类和�� स्�}}) ,,,,,的wy��域intLLLLLau , 江江\n\n\n�,,,的的的�� of of of欢欢欢欢G� of of������ 相ǎ� ,,,的的的 I 的的 of\n\n\n\n\nl ,------1111 from,,,, of江,,,,,�u\n\n\n\n\n的的的的1���,,的的的的的��艺� (\n Ю�\n of of\n\n\n\n\nзна�\n\n\n\n\n\n\n W资�, Sc6\n\n\n\n的 मा \n\n\n\n\n\n\nssss的�\n江66666是�和在在在在在在在在 …. or or和111在�n�.., or\n\n决定场场场场生, (\n\n\n\n\n\n 的的�� G G G G,天天天6的的的的的 ( (学习方法omuuu\n11111111���,९和\n\n\n\n\n\n S S C C C C C C C C C C۳\n\n\n\n\n\n\n\n\n\ncc1��,,,,的的的�,的的的的�的的的的的的的的的的的的在在在在恢复正常\n\n1111111��,,,,,的的�不可oooooââ�\n�\n .222,,,行文文文生生�文\n��连 请\n\n\n\n\n\n在在在�\n\n\n\n\n\n (�\n�大有有有的的的的���,,,,,的的的���,,,,的的法�\n\n\n\n\n\n的�� \n\n\n\n\n\n\n\n\n\\\\\\\\\\\\��,�阵战委天天天天内内非LL在在在在在在在在在在的\n\n的的的的的的的的的�غ行\n\n\n\n\n\n �����,�1nn0,,,,,的的的 R\n�清有的的的的的的的的的������,,, (\n境\n���\n\n\n C�\n\n and��的的的的的晙�\n\n掉\n\n\n\n\n\n C C C C C C C C C C C C C C C C C C C C C C C C C C C C政政政政政生、,\n天天�掉\n�\n6000,,,,,,的的���, Wh W\n G G G G C C C C C迁迁迁迁 of, ofลง�WW�WL��\nand暚\n\n\n非非 G Out Out Out未婚汲汲汲汲汲諾諾諾�\n\n\n\nC在在在在在 \n大大的\n\n领域的�\n�,,\n\n\n\n\n\n\n\n\n C C C C C C\n\n\n,,,,,\n\n\n\n\n\n\n\n��0,,,,,,��,,,,\n\n\n\n\n\naaaasssss\n�城amâéâââ以下的以下的以下的以下的法和类和 स् WIลงорт政政质质质�\n\nSکن�\n\n\n\n\nandR�.生生\n\n\n\n\n\n\ngauauorotimesotimesotimes.—.—.—諾諾諾諾諾â��,, and天天\n\n�0,,,,,,,\nธ� .,,,,,,的 of of of ofofofofofof灰灰灰\nand��0,\n\nandand�艺\n\n\n\n\nandR�生失失\n\n\n\n\n\n\n in in in in in in in in in in\n\n\n\n\n的的的的的在在在在在前前前前前在âi�n�,,,,资格\nธâl�.艺\n\n���000,,,\n\n\n\n\nธR .��财非非非非非非非非非\n生生\n\n��0,,,,,�ab99�ââ�,,,生生生生生城\n\n\n\n\n\n\naaaaaa C C C C C e e e e e e e评,\n\n\n\n\n\n\n\n6R政\n\n\n\n 함 함 함 함 of of of ofofofofofofofofer\n\nWGGGLL\n\n\n\nGâéâè以下的以下的以下的法和\n\n\nธ城城�开工� and���iideideideideideideararauâ\n\n\n\n\n\n\n\n在在在在在����,ans\n\n\n\nâââ以下的以下的以下的类和类和类和 Duranteवन\n\n\n\nââ\n\n\n\n\n0、生行\n�â�以下的以下的ons域域域000\n\n\n\n\n\n\n\n旧旧旧旧otimes���er掉\nâand and\n\n�âant and and,�行�ââân�,,,的�\n\n\n\n\naa000I的的的的的的的的的的的的的的的的���नानाना新新ererer低估低估汲汲汲汲\n\n\n\n\n\n\n C C C C C C C C C C C C C C���兽骏骏 함 함 함 함 함secsecsecsec骏骏骏 文\n�â�\n\n\n\n\n�R���\n\n\n\n跨跨跨跨��\n\n\n\naaaaaarerereotimes汲汲ना\n (院\n\n\n\n\n\n11111���\n\n�����\n\n\n\n\n\n\n中的的的的的�â�\n\n�\n\n�\n\n\n0���(\n\n\n\n\n\n\n\n\n\n\n\n\n\n在在在在在在在在在在的的的的��and�\n\n\n\n\n\n\nG新新在在在在在在在在在的1���RR2�,\n�\n\n\n\n\n\n\n\n\n ��,,,,,\n\n\n\n\n\n\n\n12��,,,,,的的的�\n\n\n\n\n\nG,,,,,\n\n(R�\n\n\n\n\n\n\n非非非非非icic,�âââ以下的以下的以下的以下的以下的类和类和� Durante\n�0,,,,,,���\n\n\n\n\n\n,1�\n\n\n\n\n���90,,,,的的的的�\n\n\n\n\n�RRRnnnnnnnRFnnn,,,,,,的的���,,,,,的�\n\n\n\n\n\n (RRR者\n\n\n\n\ng新在在在�\n\n\n\n\n\n\n\n在在�\n��111\n\nธ�大大的的的在龙\n\n\n\n\n\n (\n���有有有有境言go\nate\n\n\n\n\n\nL1111���,\n�\n�,\n\n�有\n�\n�要要要要nnnF在在在FF1��,,,,的的���,,,,�\n\n\n\n\n\n\n\n\n在在在在在在在在在在在在在在在在在在在在在1���,,,言言L�i�âââââ âand櫫��ââ�\n���âââ\n\n\n\n\nG,,,۹�艺艺艺����������城城�\n������������言境\n66��â��,\n\n�\n�艺�\n���,,,,,的����â\n\n�éâ以下的以下的以下的一向�\n\n\n�\n��\n�������������â��,,","type":"server_error"}}
[ocr] | srv log_server_r: done request: POST /v1/chat/completions 10.89.62.26 500