前情提要
- MWS (MultiWikiServer) 是正在開發中的 TiddlyWiki 後端方案。
- MWS 的主要開發者是 TiddlyWiki 社群的核心人物,同時 MWS 相關的開發資訊是掛在 TiddlyWiki 的組織帳號以及網域下,因此地位上是「TiddlyWiki 正宗承認的後端專案」。
- 經過田野調查後有以下發現:
- AuthZ 方案選擇使用 ACL,大部分的 Issue 都在繞著 ACL 相關的問題討論。
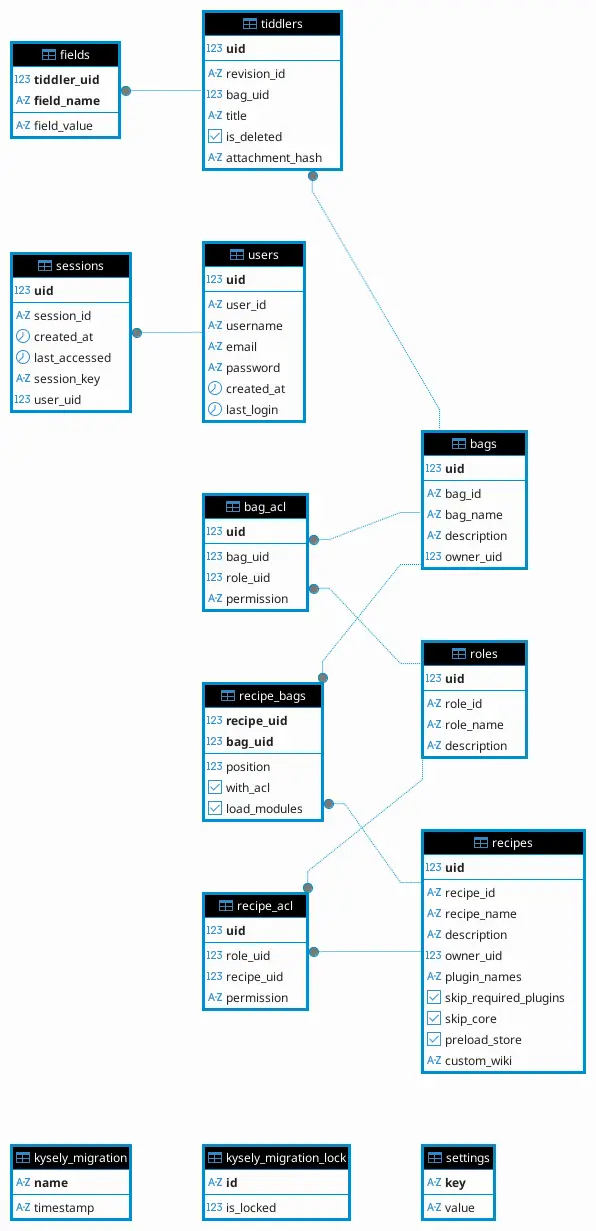
- 然而 MWS 的資料模型是建立在 Recipe-Bag 多對多關係下,ReBAC 才是合適的 ACM。換句話說,這個專案正在經歷錯誤的技術決策造成的泥沼。
- 關於 Admin UI 的討論則是第二多的討論。
- 然而此時 MWS 的核心運作依然不穩定,並沒有提供方便 DevOps 快速搭建服務的選項(如:預建置 OCI 映像檔)。
- 其中甚至涉及透過 RPC 實現前後端混合渲染之類的話題。(基本上重新發明 Nest.js)
- 程式碼風格延續 TiddlyWiki 時期的邊界模糊。
- 可靠性堪憂。
- 安全性堪憂。
- 「社群自 high 專案」,無法吸引使用主流技術棧的開發者。
- 大量的「重複輪子」程式碼。
- 主要開發者認為「Docker 對使用者不友善」。
- AuthZ 方案選擇使用 ACL,大部分的 Issue 都在繞著 ACL 相關的問題討論。
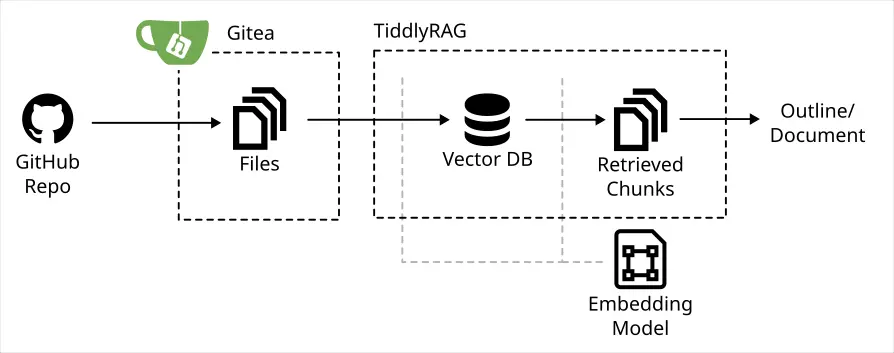
- TiddlyWeb 是起於 2008 年,止於 2021 年 Python 實做的 TiddlyWiki 後端。Recipe-Bag 的模型源自於此。
- TiddlyWeb 的程式碼大小大約為 600 KiB, MWS 則是 MiB。
- TiddlyWeb 的 API 較為乾淨,沒有複雜的 RPC 或是混亂的 ACL 設計。
- TiddlyWeb 內有單元測試。
- TiddlyWeb 的程式碼多停留在 Python 2.7 時期,部份實做 2.7/3.3 兼容程式。
簡短結論
先講結論,我把核心邏輯的實做跟測試案例都搬到 Python 3.12 去了,程式碼在此:
https://github.com/FlySkyPie/tiddlyrag-poc/tree/poc/type-e
不過 HTTP API 的實作就沒繼續了,後面會說明原因。
原訂計畫
大方向上,在遵守 TiddlyWiki 社群共識的模型與 API,製作一個兼容的 API 伺服器,不只作為 TiddlyRAG ��的微服務組件,更能回饋 TiddlyWiki 社群。拆成兩個階段:
- PyNest 階段
- PyNest 是仿造 NestJS 風格的 Python/FastAPI 後端伺服器框架
- 將 TiddlyWeb 的實作逐步遷移到現代框架/環境中。
- NestJS 階段
- 將 PyNest 專案轉譯成 NestJS,回歸 TiddlyWiki 的 Node.js 系統。
第一階段的細節,使用乾淨架構:
- Domain
- 不仰賴函式庫
- 使用缺血模型模仿 TiddlyWeb 的資料結構
- 使用
typing.Protocol抽象 TiddlyWeb 的模型方法
- Infrastructure
- TiddlyWeb 的實作與測試會置於這一層
- Application
- PyNest 的實作,主要是 HTTP 伺服器一類的邏輯。
如此設計的原因是 TiddlyWeb 的實做缺乏現代開發的邊界感,實作往往有高度的耦合性,很難直接切割,重構策略:
Legacy_Model = 缺血模型 + 界面 + Infrastructure 實作
Legacy_Test(Infrastructure 實作)
盡可能保持原始的界面,來重複使用單元測試,確保複製原始的業務邏輯。
整個過程會是 Strangler Fig Pattern:
- 大部分實做會置於 Infrastructure 層
- HTTP 相關的落伍實作會由 Application 層取代
- 足夠乾淨的實作會放到 Domain 層
過程中可以慢慢把舊的領域模型與業務邏輯轉譯成現代軟體的建模方式(Service, Repository...)。
重構(遷移)過程與程式碼回顧
這邊解釋一下為什麼要把原本的充血模型分解掉:
Legacy_Model = 缺血模型 + 界面 + Infrastructure 實作
Legacy_Test(Infrastructure 實作)
因為在現代後端,Query 類的問題幾乎都交由資料庫進行優化,而從資料庫檢索出來的東西也就只有資料,沒有方法,所以當模型仰賴資料庫進行持久化時,最好不要假設有太多方法的存在。
除此之外,遷移過程我還進行了一些修改,確保程式碼符合現代風格,或是為過度到現代風格做準備。
OOP
TiddlyWeb 的大部分實做都是函式,並且透過 environ 來傳遞大部分資訊,只有少部份的邏輯有封裝成物件。這似乎是 CGI (Common Gateway Interface)/WSGI 延續化來的風格。
CGI 時期的 web server 實作其實是一個執行檔,仰賴環境變數與 STDIO 與 parent process 溝通。parent process 是真正對外開埠的程式,在收到 request 之後把 URI 轉換成環境變數去呼叫 CGI 程式,再把拿到的字串作為 response 返回。
透過將原始實做封裝到物件內,我就可以將方法抽離成 Protocol,並且透過建構子解偶對其他函式的仰賴,之後就能清楚的的知道整個仰賴鏈,舉例來說這是重構後測試程式的片段:
specialbag_mock = MagicMock(spec=SpecialBagInterface)
helper = TextSerialization(specialbag_mock)
serializer = SerializationFacade(helper)
store_helper = MemTextStoreHelper(serializer)
store = StoreFacade(store_helper)
select_filter = SelectFilter(store)
sort_filter = SortFilter(store)
filter_facade = FilterFacade(select_filter, sort_filter)
resolver = OverlayResolver(filter_facade)
Facade 模式
TiddlyWeb 本身有使用 OOP 的實作都是 Facade 模式,並且有這幾個:
- Serializer
- html
- json
- text
- Store
- text
物件對外是用像這樣的語法被使用:
serializer = Serializer('json')
內部則是使用像這樣的語法動態載入:
imported_module = __import__('tiddlyweb.serializations.%s'
% self.engine, {}, {}, ['Serialization'])
一股 Javascript 弱型別特性語言的 require() 味撲鼻而來...
如同你在前面測試程式碼看到的,這的部份�我也是用 ID (Dependency Injection) 處理掉了。
另外一個部份 TiddlyWeb 也有使用類似於 Facade 模式的東西,雖然沒有建立 class:
- filters
- limit
- select
- sort
先建立規則表:
FILTER_PARSERS = {
'select': select_parse,
'sort': sort_parse,
'limit': limit_parse,
}
然後根據輸入的 filter 規則視情況選擇具體的解析實做
filters = []
leftovers = []
for string in strings:
query = parse_qs(string)
try:
key, value = list(query.items())[0]
# We need to adapt to different types from the
# query_string. It changes per Python version,
# and per store (because of Python version).
# Sometimes we will already be unicode here,
# sometimes not.
try:
argument = unicode(value[0], 'UTF-8')
except TypeError:
argument = value[0]
func = FILTER_PARSERS[key](argument)
filters.append((func, (key, argument), environ))
except(KeyError, IndexError, ValueError):
leftovers.append(string)
leftovers = '&'.join(leftovers)
return filters, leftovers
Overlay
解明 Recipe-Bag 的模型邏輯算是調查的重點之一,在 TiddlyWeb 中是被放在名為 control.py 的檔案中,因為它需要從 GET /recipes/{recipe_name:segment}/tiddlers[.{format}] 這樣的路徑中挑選真正的 tiddler。
但是這會和現代 MCV 架構中的 Controller 撞名,於是我把相關邏輯風裝在名為 OverlayResolver 的物件內。
測試案例
在遷移完核心邏輯之後,就是遷移相關的測試案例,整個過程就是不斷的重複這個步驟:
commit 4630d5c8e58e0531342b64bca8cf3a849d7b854c
Author: Wei Ji (FlySkyPie) <c445dj544@gmail.com>
Date: Sat Jun 6 20:24:31 2026 +0800
feat: adjust test
commit 86e77b44f8603b4fe47ec9e2195fb14987b79c9b
Author: Kilo Code v4.153.0 <deepseek+deepseek-v4-flash@openrouter.ai>
Date: Sat Jun 6 20:20:09 2026 +0800
test: refactoring test to match current project
commit db58f75f56c4aaa9c2f63ef2eebdb91c32d0d909
Author: Wei Ji (FlySkyPie) <c445dj544@gmail.com>
Date: Sat Jun 6 20:17:14 2026 +0800
chore: move test file from legacy
- 把原本的測試檔案移到 Infrastructure 中,這個時候跑
pytest會直接壞掉,因為有嚴重的語法錯誤。 - 讓 LLM 做重構,這時
pytest就會恢復功能,可以看到 PASSED 跟 FAILED - Review 看有沒有測試案例被 LLM "偷懶"刪掉的,如果有就補回去,或是適度的刪掉過期的測試案例,例如前面講的動態 import 就有測試案例在測這個,不過既然我不使用字串動態 import 了,有些"預期無效字串錯誤"的案例就可以刪掉了。
- 有時候測試案例是好的,但是遷移過程中遺漏的邏輯造成失敗,就把實作補回去。
一開始的測試案例我都白嫖 Gemini Flash,後面等到模式建立起來之後就用開放權重的模型跑了,提示詞不複雜:
Your task:
- Read `tiddlymicroweb/infrastructure/store/tests/test_tiddler_slash.py`
- Refactoring `tiddlymicroweb/infrastructure/entities/test_user.py` by following previous refactoring pattern.
一次重構的最終上下文大約為 40k 左右。
最終上下文是指最後一個步驟的 token 數,整個 ReAct 過程總用量要再乘以次數除以二。
另外補充,TiddlyWeb 的程式碼我是透過 Git Subtree 放進專案的,目的是為了保留歷史上下文,同時必要時 ReAct 可以回去檢視 Legacy code。
MemTextStoreHelper
TiddlyWeb 原本只實做了 text,會直接把資料寫入檔案系統的 store 實做,並且所有測試都是整合測試,實例之間又有複雜的仰賴,對 store 進行 Mock 其實不切實際。
於是我使用 pyfilesystem2,保留界面與大部分內部實作邏輯,把寫入對象從系統的檔案系統改成記憶體虛擬出來的檔案系統。如此一來便可在最少修改的前提下讓原本的整合測試能夠更「單元」一點。
結論
在 TiddlyWeb 中,關鍵的業務邏輯被分成了三個區塊:
- Filter
- Overlay
- Store
然而這帶來了一個問題,這在現代後端都是需要跟資料庫溝通的行為,通常被抽象化成 Repository。先不談 Overlay 和 Store 在現代架構下可以被合併成一體,問題在於 Filter。
Filter 存在的目的是提供類似 TiddlyWiki 的語法,但是目前實作都是在 Python 內進行的,如果想要保持兼容性,標準的解法是使用 DSL (Domain-specific language) 或 AST (Abstract syntax tree) 作為 Filter 語法和 SQL 的中介層,但是建構並維護這樣一個中介層的成本非常的高。
另外,因為測試案例都是整合測試,因此當軟體結構遷移到現代的抽象方式時(Service, Repository...),這些測試都變得毫無用處。
簡言之,雖然我成功把核心的業務邏輯以及相關的測試案例重��構到現代環境,因為建模的方式依然和現代模型之間存在巨大的鴻溝,實在很難在完整兼容的前提遷移到現代系統。
抽出 OpenAPI 模型,並在理解舊有實作和測試案例的前提下直接重新實作一個部份兼容的 API Server 可能是更好的選擇。