
前情提要
作為一個閃亮事物症候群工程屍,挖坑從來不手軟,TiddlyRAG 是一個新坑,主要是關於 RAG (Retrieval-augmented generation),於是我想先調查一下市面上的開源專案怎麼呈現 RAG 的。
找著找著發現一個不錯的清單,於是想說從中把能跑得都跑過一遍吧!話雖如此,對我而言有幾個前提條件:
- 是 Web App
基於 HTTP 的應用程式對我而言才有參考價值,因此桌面應用程式 (Desktop App) 或終端機應用 (TUI) 不在評估範圍內。
- 有預編 OCI (Open Container Initiative) 映像檔
我的標準環境是 Dcoker/kubernetes,並且我也不想額外自行編譯映像檔,因此:只支援透過 uv/pip 安裝的 Python 軟體或是有提供 Dockerfile 但是沒有預編的方案同樣不考慮。
- 有 RAG 機制
RAG 是我這次主要想觀察的功能,也就是匯入/上傳檔案、嵌入、檢索...,其他類型的 LLM 應用程式我暫時不列入考慮。話是這麼說,不過要是我下載之後才發現不具備 RAG 功能,還是會寫個簡單的紀錄。
評測與調查重點
以上是大前提,接著是評估的面向:
- OCI 層分析
因為我的無線網路環境有點惡劣,根據經驗單層超過 1GB 的 OCI 映像檔幾乎都拉不下來。另外如果單一映像檔過大,在微服務架構下的自動擴展機制會不夠友善,因為載入與啟動時間比較長。所以 OCI 大小以及分層尺寸是我會考慮的其中一點。
實際上還是可以透過 regclient 的 regctl 指令修改 chunk 大小下載下來,只是會繞過我的 Homelab 本地快取/鏡像機制,所��以視同拉不下來。
- 微服務編排與重用
雲原生環境會透過切割 OCI 的方式實現職責分離,並且往往會重複使用一些組件,例如:SQL 資料庫、S3 實例、記憶體快取...。一方面是透過職責分離,確保使用的是足夠成熟的方案,而不是自行研發;二方面是透過特定的界面整合實現解偶,可以視情況抽換實做(如:自用輕量 vs 商用可靠)。這個 LLM 應用程式是屬於微服務架構還是單體式架構也是我的觀察重點之一。
- 嵌入資料可維護性
就算不談 RAG 這樣的現代系統,在傳統 ETL (Extract, Transform, Load) 的領域中,資料的可追朔、可審計是基本中的基本。更別提對 RAG 這樣的系統而言,可靠度高度受到資料庫的品質影響。
- 提示詞與 LLM 呼叫策略
關於 LLM 可觀測性 (Observability),也就是觀察應用程式的提示詞,過去我寫了幾篇相關的文章提及:
不過一直沒有系統性的紀錄下來,趁這個機會好好的寫下來吧。
AnythingLLM
OCI 構成
podman image tree
podman image tree docker.io/mintplexlabs/anythingllm:1.11.0
Image ID: ff8367ba40cb
Tags: [docker.io/mintplexlabs/anythingllm:1.11.0]
Size: 3.162GB
Image Layers
├── ID: e8bce0aabd68 Size: 80.64MB
├── ID: 9e7e2ecd31b0 Size: 1.024kB
├── ID: 3228a4f46016 Size: 1.179GB
├── ID: 7282d320f8f9 Size: 24.58kB
├── ID: c5ee10132db1 Size: 4.608kB
├── ID: 90a5b49ea903 Size: 3.584kB
├── ID: 42577cf50556 Size: 17.92kB
├── ID: 14c973612c97 Size: 3.584kB
├── ID: b6a11ed79c58 Size: 1.024kB
├── ID: d7f4147261e4 Size: 1.024kB
├── ID: d35130223185 Size: 2.908MB
├── ID: 5a8262e26991 Size: 1.024kB
├── ID: 7c2038cbfeb5 Size: 964.3MB
├── ID: 8f041fd68349 Size: 1.024kB
├── ID: ab54a4950e52 Size: 484.4kB
├── ID: 647fb5404ce3 Size: 1.024kB
├── ID: 40c5efdad8a9 Size: 921.2MB
├── ID: 63204dd64df9 Size: 1.024kB
├── ID: 58d9f478d9ba Size: 1.024kB
└── ID: 42428f8f7df8 Size: 12.48MB Top Layer of: [docker.io/mintplexlabs/anythingllm:1.11.0]
映像檔整體約為 3GB,但是單層不超過 1GB。
簡單對話
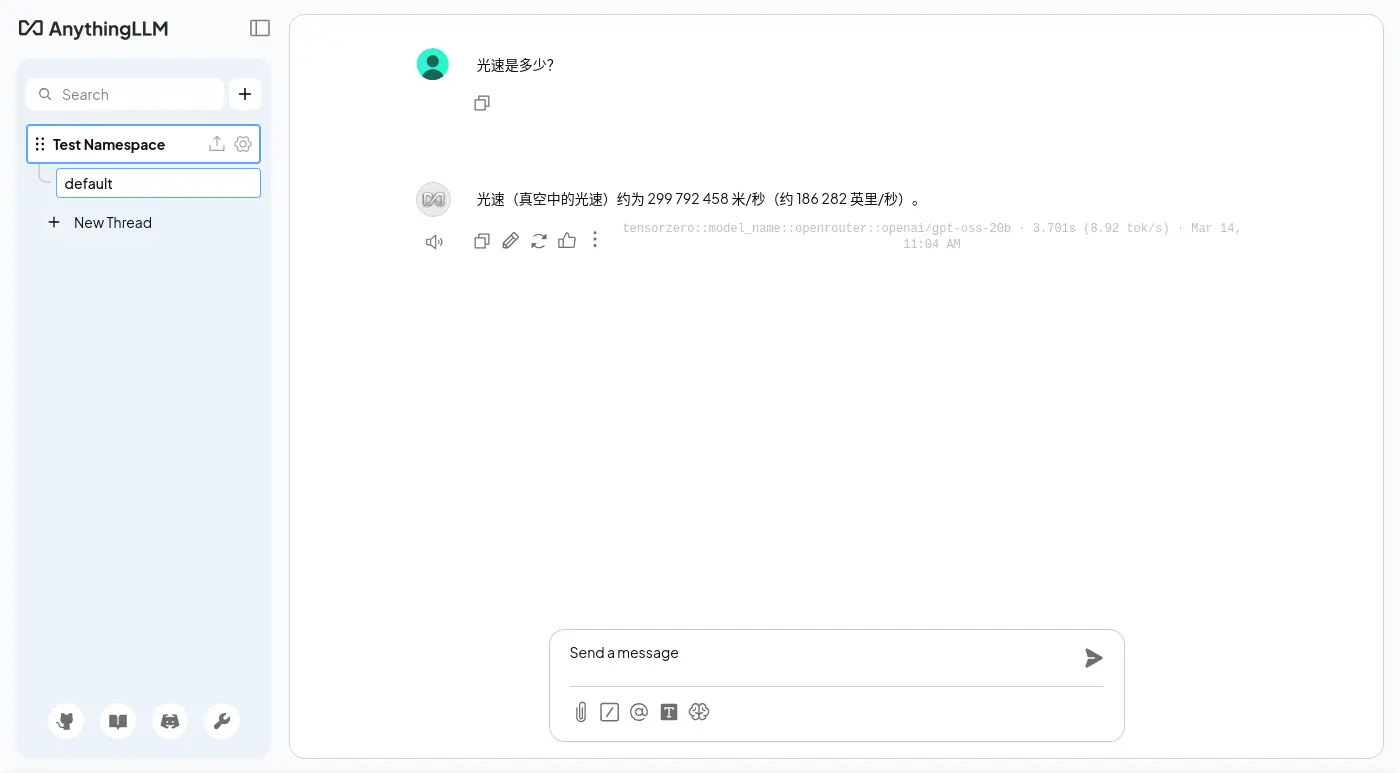
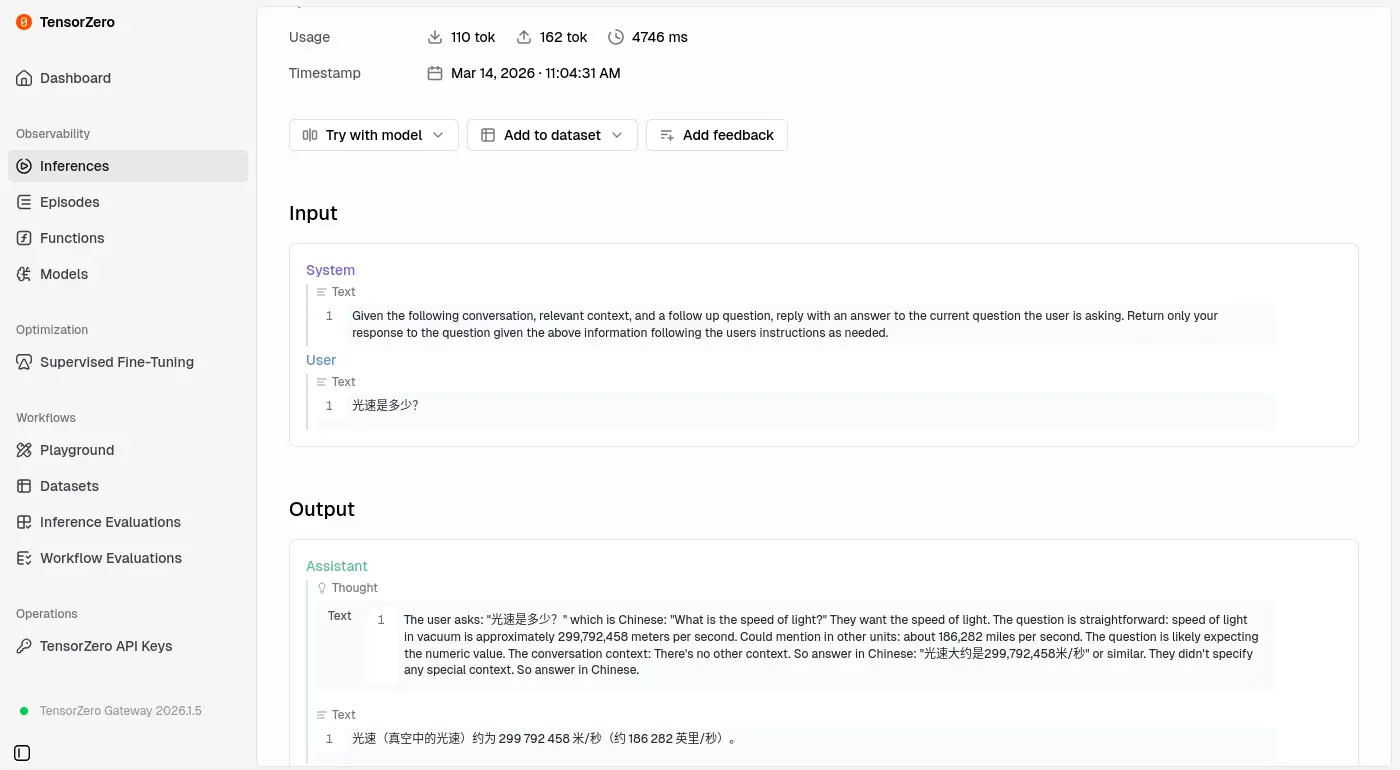
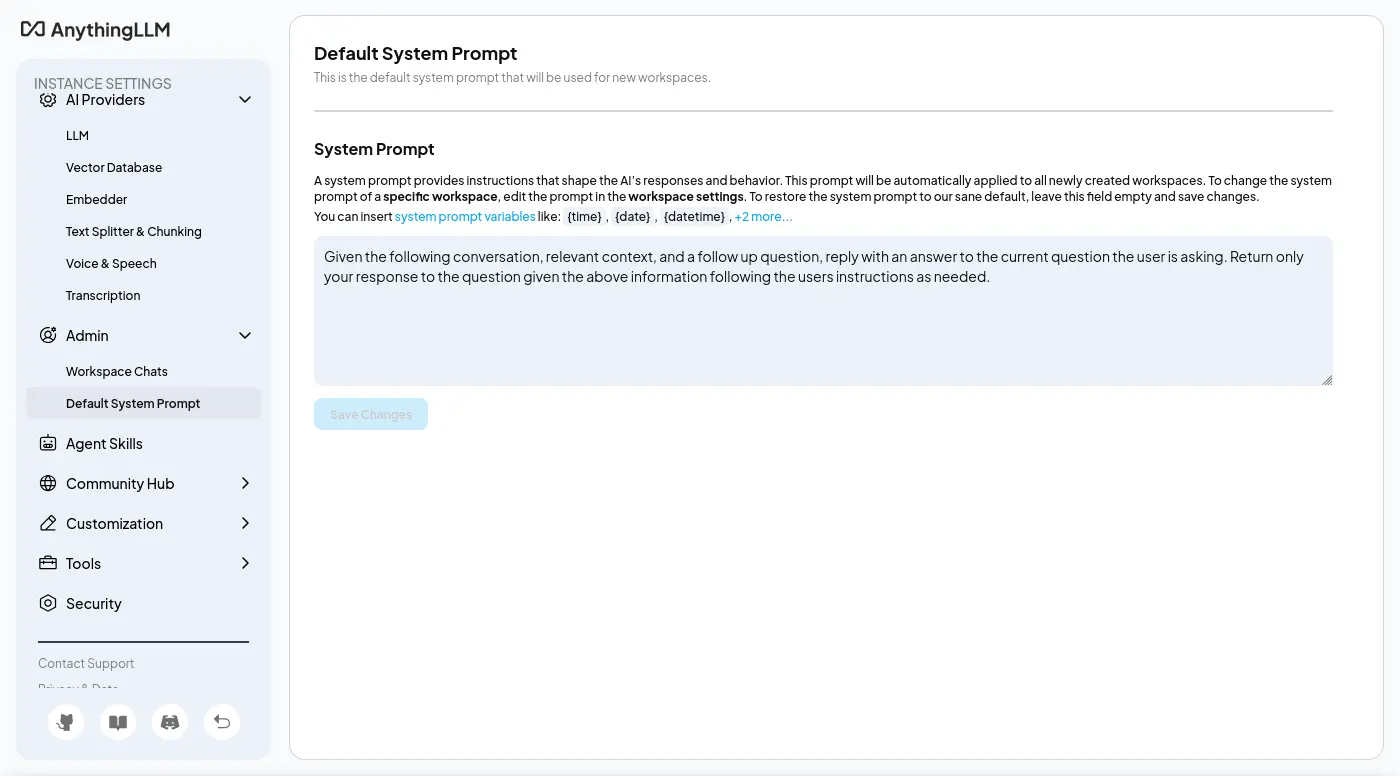
預設系統提示詞是可以修改的:
URL 訪問能力
第一次測試是失敗的,
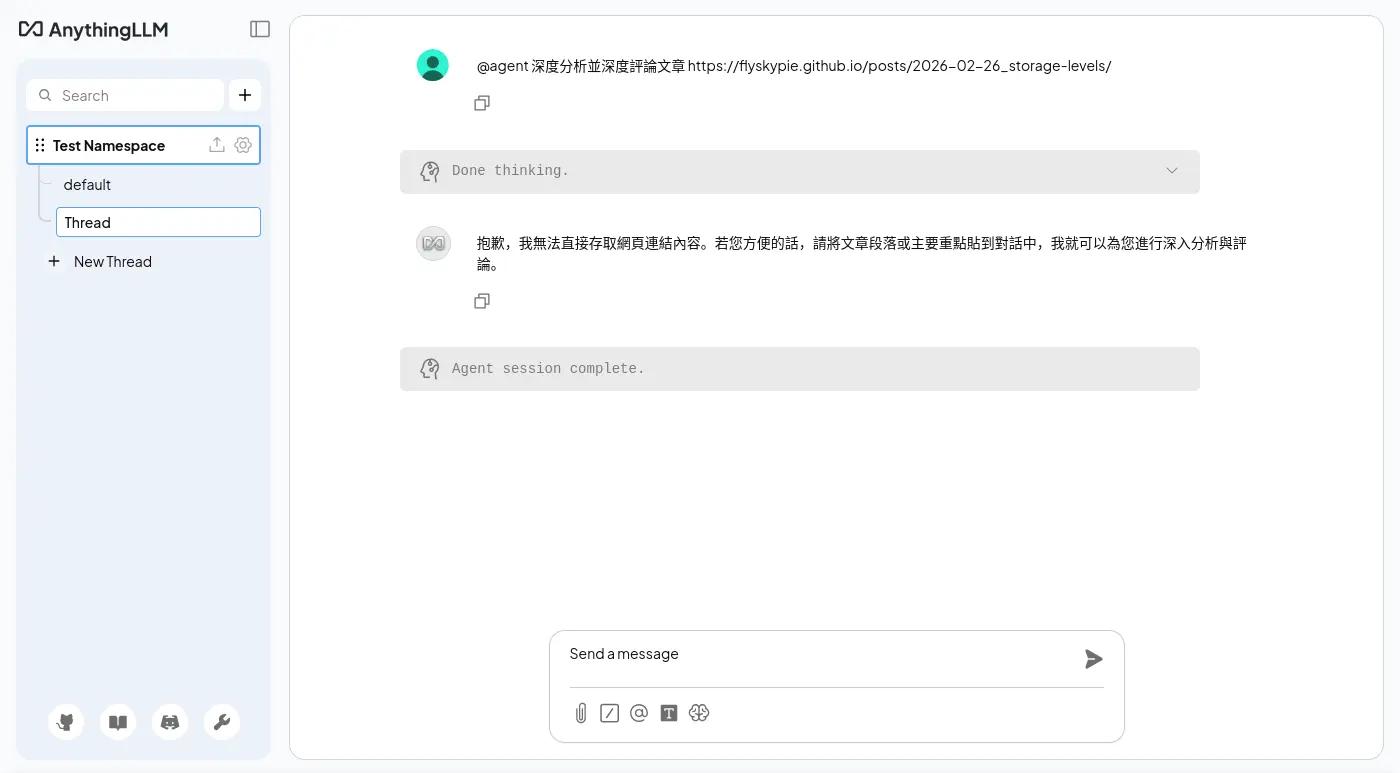
不知道為什麼沒有回應正確的格式:
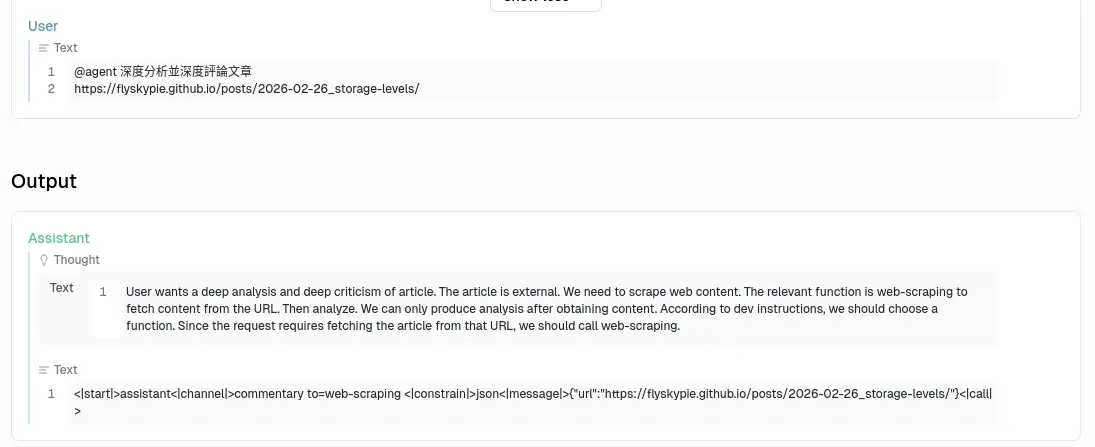
失敗的後台紀錄:
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::openai/gpt-oss-20b] Untooled.stream - will process this chat completion.
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::openai/gpt-oss-20b] Invalid function tool call: Missing name or arguments in function call..
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::openai/gpt-oss-20b] Will assume chat completion without tool call inputs
是 openai/gpt-oss-20b 的性能太差勁還是提示詞下太爛?
是說 OpenAI API 明明就支援直接傳入工具,不知道開發者在想什麼。
這是目前 Agentic Programing (俗稱 Vibe Coding) 的標準實現方式的說。
換成貴一點的模型(qwen/qwen3.5-35b-a3b)就可以運作了:
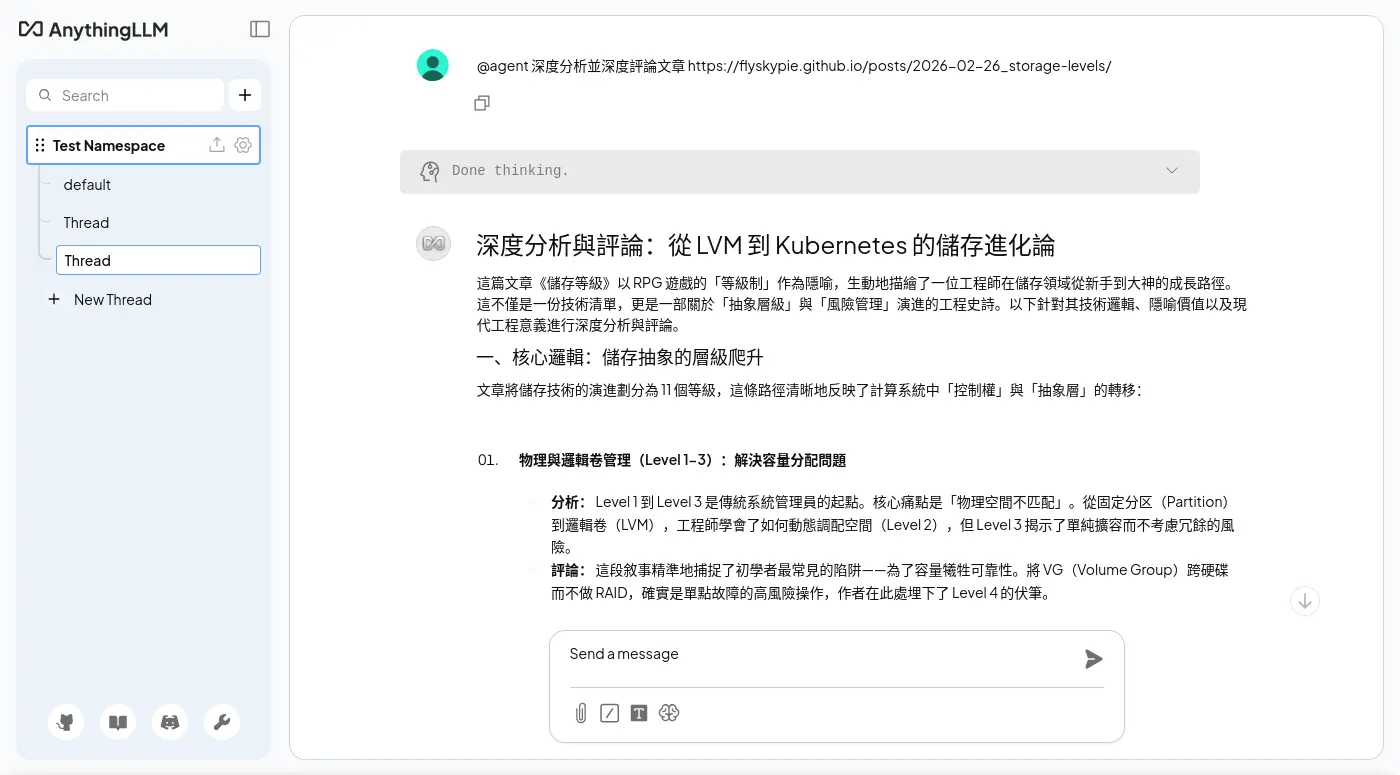
主要分成兩次呼叫,我不知道為什麼其中一個重複了兩次,

系統提示詞:
系統提示詞一:
You are a program which picks the most optimal function and parameters to call.
DO NOT HAVE TO PICK A FUNCTION IF IT WILL NOT HELP ANSWER OR FULFILL THE USER'S QUERY.
When a function is selection, respond in JSON with no additional text.
When there is no relevant function to call - return with a regular chat text response.
Your task is to pick a **single** function that we will use to call, if any seem useful or relevant for the user query.
All JSON responses should have two keys.
'name': this is the name of the function name to call. eg: 'web-scraper', 'rag-memory', etc..
'arguments': this is an object with the function properties to invoke the function.
DO NOT INCLUDE ANY OTHER KEYS IN JSON RESPONSES.
Here are the available tools you can use an examples of a query and response so you can understand how each one works.
-----------
Function name: rag-memory
Function Description: Search against local documents for context that is relevant to the query or store a snippet of text into memory for retrieval later. Storing information should only be done when the user specifically requests for information to be remembered or saved to long-term memory. You should use this tool before search the internet for information. Do not use this tool unless you are explicitly told to 'remember' or 'store' information.
Function parameters in JSON format:
{
"action": {
"type": "string",
"enum": [
"search",
"store"
],
"description": "The action we want to take to search for existing similar context or storage of new context."
},
"content": {
"type": "string",
"description": "The plain text to search our local documents with or to store in our vector database."
}
}
Query: "What is AnythingLLM?"
JSON: {"name":"rag-memory","arguments":{"action":"search","content":"What is AnythingLLM?"}}
Query: "What do you know about Plato's motives?"
JSON: {"name":"rag-memory","arguments":{"action":"search","content":"What are the facts about Plato's motives?"}}
Query: "Remember that you are a robot"
JSON: {"name":"rag-memory","arguments":{"action":"store","content":"I am a robot, the user told me that i am."}}
Query: "Save that to memory please."
JSON: {"name":"rag-memory","arguments":{"action":"store","content":"<insert summary of conversation until now>"}}
-----------
-----------
Function name: document-summarizer
Function Description: Can get the list of files available to search with descriptions and can select a single file to open and summarize.
Function parameters in JSON format:
{
"action": {
"type": "string",
"enum": [
"list",
"summarize"
],
"description": "The action to take. 'list' will return all files available with their filename and descriptions. 'summarize' will open and summarize the file by the a document name."
},
"document_filename": {
"type": "string",
"x-nullable": true,
"description": "The file name of the document you want to get the full content of."
}
}
Query: "Summarize example.txt"
JSON: {"name":"document-summarizer","arguments":{"action":"summarize","document_filename":"example.txt"}}
Query: "What files can you see?"
JSON: {"name":"document-summarizer","arguments":{"action":"list","document_filename":null}}
Query: "Tell me about readme.md"
JSON: {"name":"document-summarizer","arguments":{"action":"summarize","document_filename":"readme.md"}}
-----------
-----------
Function name: web-scraping
Function Description: Scrapes the content of a webpage or online resource from a provided URL.
Function parameters in JSON format:
{
"url": {
"type": "string",
"format": "uri",
"description": "A complete web address URL including protocol. Assumes https if not provided."
}
}
Query: "What is anythingllm.com about?"
JSON: {"name":"web-scraping","arguments":{"url":"https://anythingllm.com"}}
Query: "Scrape https://example.com"
JSON: {"name":"web-scraping","arguments":{"url":"https://example.com"}}
-----------
Now pick a function if there is an appropriate one to use given the last user message and the given conversation so far.
系統提示詞二:
Given the following conversation, relevant context, and a follow up question, reply with an answer to the current question the user is asking. Return only your response to the question given the above information following the users instructions as needed.
關於呼叫工具,兩次 LLM 的回應一次給 「包含 JSON Code 的 Markdown」另外一次給「JSON」,不知道是不是重複呼叫的原因。
後台紀錄:
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b] Untooled.stream - will process this chat completion.
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b] Valid tool call found - running web-scraping.
[anythingllm] | [backend] info: [AgentHandler] [debug]: @agent is attempting to call `web-scraping` tool {
[anythingllm] | "url": "https://flyskypie.github.io/posts/2026-02-26_storage-levels/"
[anythingllm] | }
[anythingllm] | [backend] info: [EncryptionManager] Loaded existing key & salt for encrypting arbitrary data.
[anythingllm] | [collector] info: -- Working URL https://flyskypie.github.io/posts/2026-02-26_storage-levels => (captureAs: text) --
[anythingllm] | [collector] info: -- URL determined to be text/html (web) --
[anythingllm] | [backend] info: [TokenManager] Initialized new TokenManager instance for model: tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b] Untooled.stream - will process this chat completion.
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b] Cannot call web-scraping again because an exact duplicate of previous run of web-scraping.
[anythingllm] | [backend] info: [AgentLLM - tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b] Will assume chat completion without tool call inputs.
[anythingllm] | [backend] info: [TELEMETRY SENT] {"event":"agent_chat_sent","distinctId":"9d1b8903-e002-42b7-8ea2-222fedeec43e","properties":{"runtime":"docker"}}
[anythingllm] | prisma:info Starting a sqlite pool with 25 connections.
[anythingllm] | [backend] info: [113:248]: No direct uploads path found - exiting.
[anythingllm] | [bg-worker][cleanup-orphan-documents] info: [113:248]: No direct uploads path found - exiting.
[anythingllm] | [backend] warn: Child process exited with code 0 and signal null
[anythingllm] | [backend] info: Worker for job "cleanup-orphan-documents" exited with code 0
[anythingllm] | [backend] info: Client took too long to respond, chat thread is dead after 300000ms
[anythingllm] | [backend] info: [AgentHandler] End 7f77b729-bd0c-4f8d-8cb1-df5eeed30117::generic-openai:tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b
嵌入文件
為了開箱即用,AnythingLLM 內建了向量資料庫跟嵌入模型(檔案依然需要從 Hugging Face 下載)的功能。
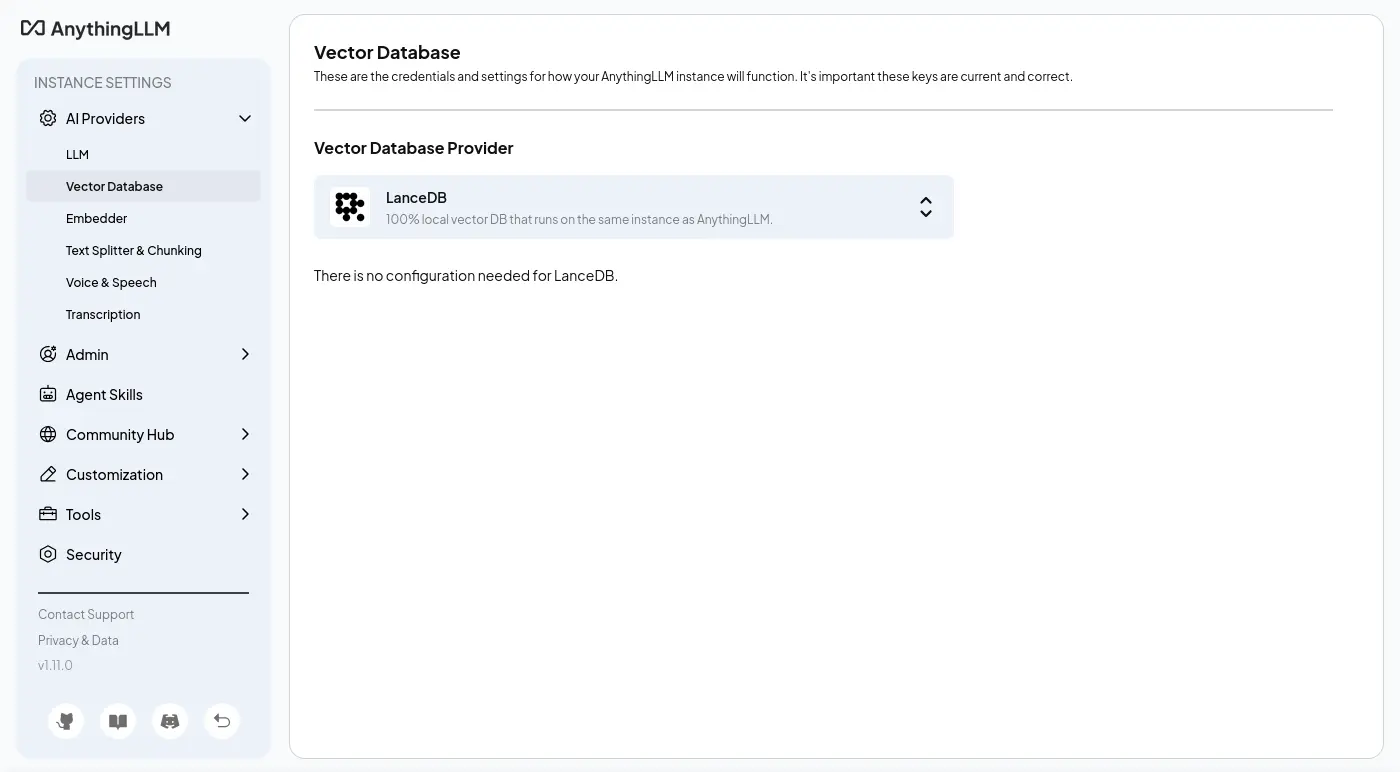
嵌入相關的 UI 非常簡陋,甚至連自己的分頁都沒有,只有彈出視窗,可見 AnythingLLM 是一款十分 Chat 本位的應用程式:
只有觸發向量索引才會顯示部份的切塊:
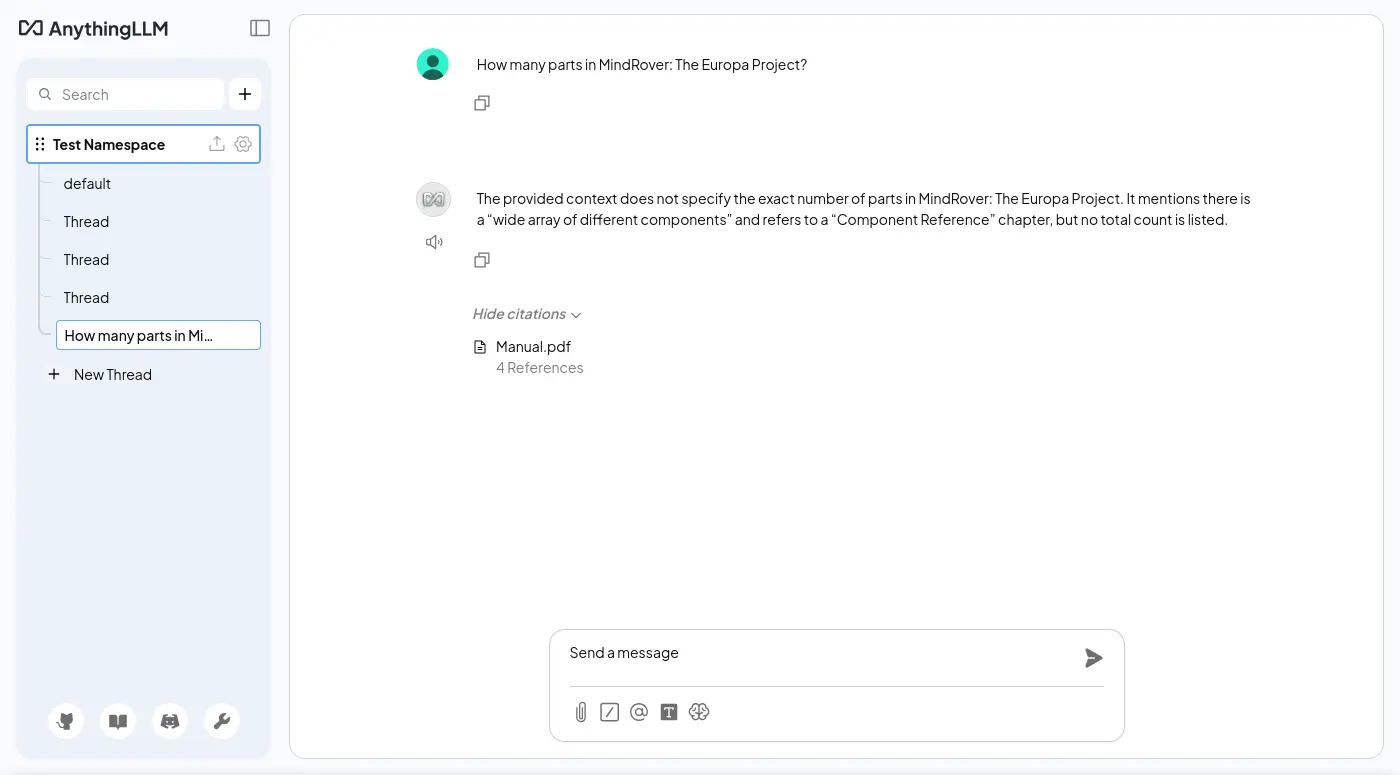
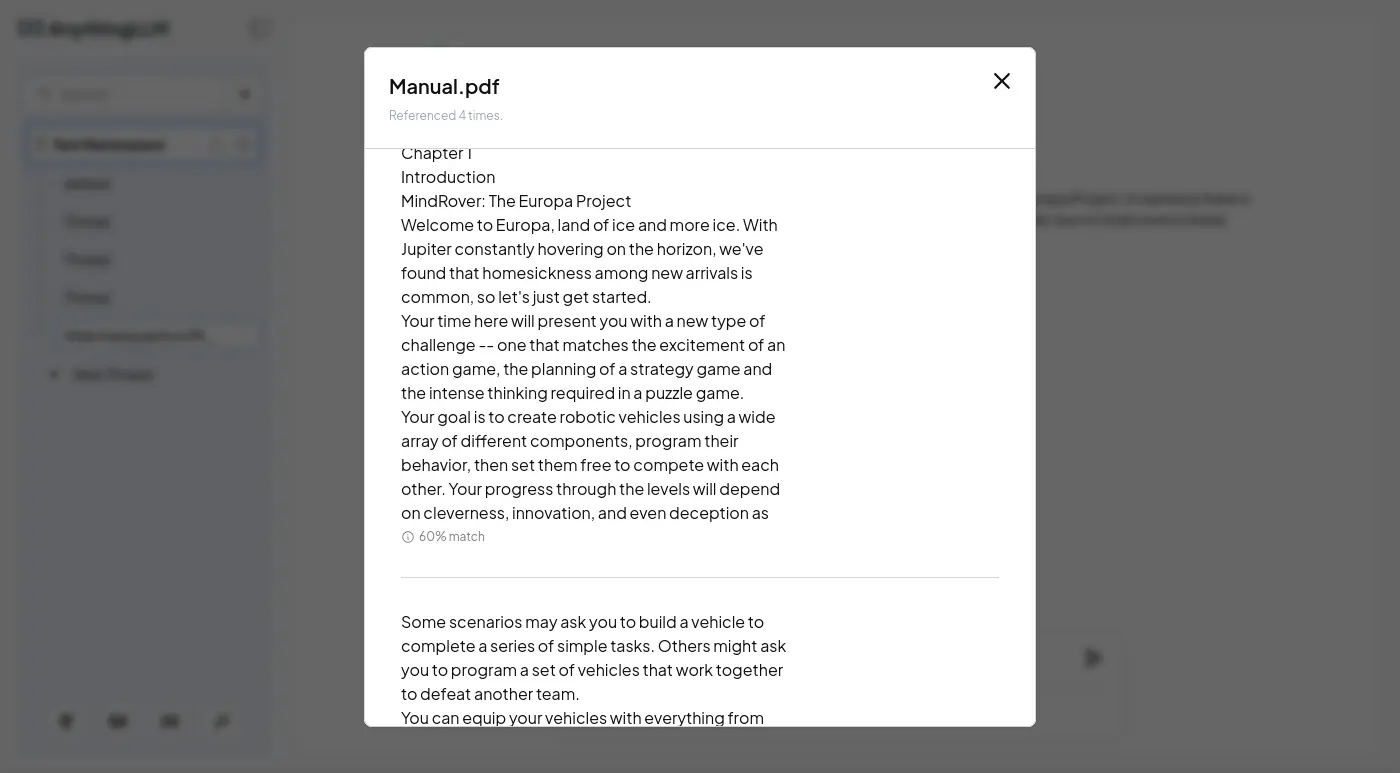
沒有找到界面可以瀏覽或編輯已經被嵌入的資料。
系統提示詞
Given the following conversation, relevant context, and a follow up question, reply with an answer to the current question the user is asking. Return only your response to the question given the above information following the users instructions as needed.
Context:
[CONTEXT 0]:
<document_metadata>
sourceDocument: Manual.pdf
published: 3/14/2026, 8:13:12 AM
</document_metadata>
Chapter 3
The Console...........................................32
Chapter 4
Component Reference..............................46
Weapon Statistics.................................61
Chapter 5
Credits..................................................62Chapter 1
4
Chapter 1
Introduction
MindRover: The Europa Project
Welcome to Europa, land of ice and more ice. With
Jupiter constantly hovering on the horizon, we've
found that homesickness among new arrivals is
common, so let's just get started.
Your time here will present you with a new type of
challenge -- one that matches the excitement of an
action game, the planning of a strategy game and
the intense thinking required in a puzzle game.
Your goal is to create robotic vehicles using a wide
array of different components, program their
behavior, then set them free to compete with each
other. Your progress through the levels will depend
on cleverness, innovation, and even deception as
[END CONTEXT 0]
[CONTEXT 1]:
<document_metadata>
sourceDocument: Manual.pdf
published: 3/14/2026, 8:13:12 AM
</document_metadata>
Some scenarios may ask you to build a vehicle to
complete a series of simple tasks. Others might ask
you to program a set of vehicles that work together
to defeat another team.
You can equip your vehicles with everything from
rocket launchers to radars to speakers. You can
program them to do anything from following a
track, to finding a path through a maze, to seeking
and destroying other vehicles. The behaviors you
can create are limitless -- and the game will grow
with your abilities.
There are five basic steps in playing MindRover.Chapter 2
8
Choose a
Scenario
First, choose a scenario or challenge. Each one has
a different task or competition, and MindRover
supports several different styles of scenario.
Choose a
Vehicle
Next, you choose a chassis on which you will place
the components for your vehicle. There are
wheeled, treaded and hovercraft type chassis in
varying sizes.
Add
Components
Next you load up your vehicle with the components
[END CONTEXT 1]
[CONTEXT 2]:
<document_metadata>
sourceDocument: Manual.pdf
published: 3/14/2026, 8:13:12 AM
</document_metadata>
you tackle some of the more challenging scenarios.
Share your successes, get advice, download new
challenges and compete with others by visiting the
MindRover website at www.mindrover.com.
MindRover probably isn't quite like anything you've
seen before, so please give yourself a chance to
learn it. Go through the in game tutorials and use
the F1 key for help along the way.
Ready? Free your mind, grab your mouse, and
enter into the world of MindRover!Introduction
5
Quick Start
For the fastest introduction to MindRover, follow
these steps:
Create a new user name and log in. Your user
name will be used to help identify the vehicles
you build.
Go through the first 2 or 3 tutorials in the game
following the tutorial prompts.
Click on Sports category, and try Sumo Hover.
There is a tutorial vehicle (half-built) available
to get you started or you can start with an
empty chassis.
After that you should have a pretty good idea of
how to go off and build your own rovers.
[END CONTEXT 2]
[CONTEXT 3]:
<document_metadata>
sourceDocument: Manual.pdf
published: 3/14/2026, 8:13:12 AM
</document_metadata>
Don’t forget to visit www.mindrover.com for hints,
tips, and competitors. You’ll find an active and
growing MindRover community.Chapter 1
6
Using This Manual
ConceptsThe Concepts section describes essential MindRover
concepts in some detail. You will learn about
scenarios, vehicles, components, wiring, and
competitions. You can read this chapter before you
play to get a good feel for all aspects of the game.
But if you like to jump right in and get started, just
go to the first tutorial and come back to this chapter
later.
ConsoleThe Console section goes into detail on each of the
user interface screens. You can read it before you
start, or just use it as a reference after you have
started playing the game.
ComponentsThis chapter gives you specific information on each
component in the game, listed alphabetically.
Within the game, click on a component and press
F1 to get more details and examples.
Start with the
tutorials
[END CONTEXT 3]
編排與構成
這個是開箱即用的單服務模式:
docker-compose.yaml
services:
anythingllm:
image: docker.io/mintplexlabs/anythingllm:1.11.0
ports:
- 3001:3001
volumes:
- anythingllm-data:/app/server/storage
environment:
- SERVER_PORT=3001
- STORAGE_DIR=/app/server/storage
- UID=1000
- GID=1000
- LLM_PROVIDER=generic-openai
- GENERIC_OPEN_AI_BASE_PATH=http://tensorzero.api.gas.arachne/openai/v1
- GENERIC_OPEN_AI_MODEL_PREF=tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b
- GENERIC_OPEN_AI_MODEL_TOKEN_LIMIT=4096
- GENERIC_OPEN_AI_API_KEY=ANY
volumes:
anythingllm-data:
接著是把嵌入跟向量資料庫打散的微服務模式:
docker-compose.yaml
services:
anythingllm:
image: docker.io/mintplexlabs/anythingllm:1.11.0
restart: always
ports:
- 3001:3001
volumes:
- anythingllm-data:/app/server/storage
environment:
- SERVER_PORT=3001
- STORAGE_DIR=/app/server/storage
- UID=1000
- GID=1000
- LLM_PROVIDER=generic-openai
- GENERIC_OPEN_AI_BASE_PATH=http://tensorzero.api.gas.arachne/openai/v1
- GENERIC_OPEN_AI_MODEL_PREF=tensorzero::model_name::openrouter::qwen/qwen3.5-35b-a3b
- GENERIC_OPEN_AI_MODEL_TOKEN_LIMIT=4096
- GENERIC_OPEN_AI_API_KEY=ANY
- EMBEDDING_ENGINE=generic-openai
- EMBEDDING_MODEL_PREF=ANY
- EMBEDDING_MODEL_MAX_CHUNK_LENGTH=1024
- EMBEDDING_BASE_PATH=http://llama-cpp:8080/v1
- GENERIC_OPEN_AI_EMBEDDING_API_KEY='ANY'
- GENERIC_OPEN_AI_EMBEDDING_MAX_CONCURRENT_CHUNKS=4
- GENERIC_OPEN_AI_EMBEDDING_API_DELAY_MS=100
- VECTOR_DB=milvus
- MILVUS_ADDRESS=http://milvus:19530
depends_on:
- llama-cpp
- milvus
llama-cpp:
image: ghcr.io/ggml-org/llama.cpp:server-vulkan
restart: always
devices:
- /dev/dri/:/dev/dri/
ports:
- 8080:8080
entrypoint: /app/llama-server
environment:
- HF_ENDPOINT=http://huggingface.mirrors.solid.arachne
volumes:
- llama-cpp-cache:/root/.cache/llama.cpp
command:
- --hf-repo
- Qwen/Qwen3-Embedding-8B-GGUF
- --hf-file
- Qwen3-Embedding-8B-Q6_K.gguf
- --embeddings
- --pooling
- mean
- --ctx-size
- "2048"
- --batch-size
- "1024"
- --ubatch-size
- "2048"
- --gpu-layers
- "999"
# - --no-mmap
- --flash-attn
- on
- --no-webui
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 10s
timeout: 20s
retries: 3
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.25
restart: always
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- etcd-data:/etcd
command: etcd -advertise-client-urls=http://etcd:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: docker.io/minio/minio:RELEASE.2024-12-18T13-15-44Z
restart: always
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- minio-data:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
milvus:
container_name: milvus-standalone
image: docker.io/milvusdb/milvus:v2.6.11
command: ["milvus", "run", "standalone"]
restart: always
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
MQ_TYPE: woodpecker
volumes:
- milvus-data:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
attu:
image: docker.io/zilliz/attu:v2.6
restart: always
environment:
- MILVUS_URL=http://milvus:19530
ports:
- 8090:3000
depends_on:
- milvus
volumes:
anythingllm-data:
llama-cpp-cache:
minio-data:
milvus-data:
etcd-data:
使用 llama.cpp 和 Qwen/Qwen3-Embedding-8B-GGUF 嵌入模型,並且用 Milvus 作為向量資料庫,順手測了一下雙語索引:
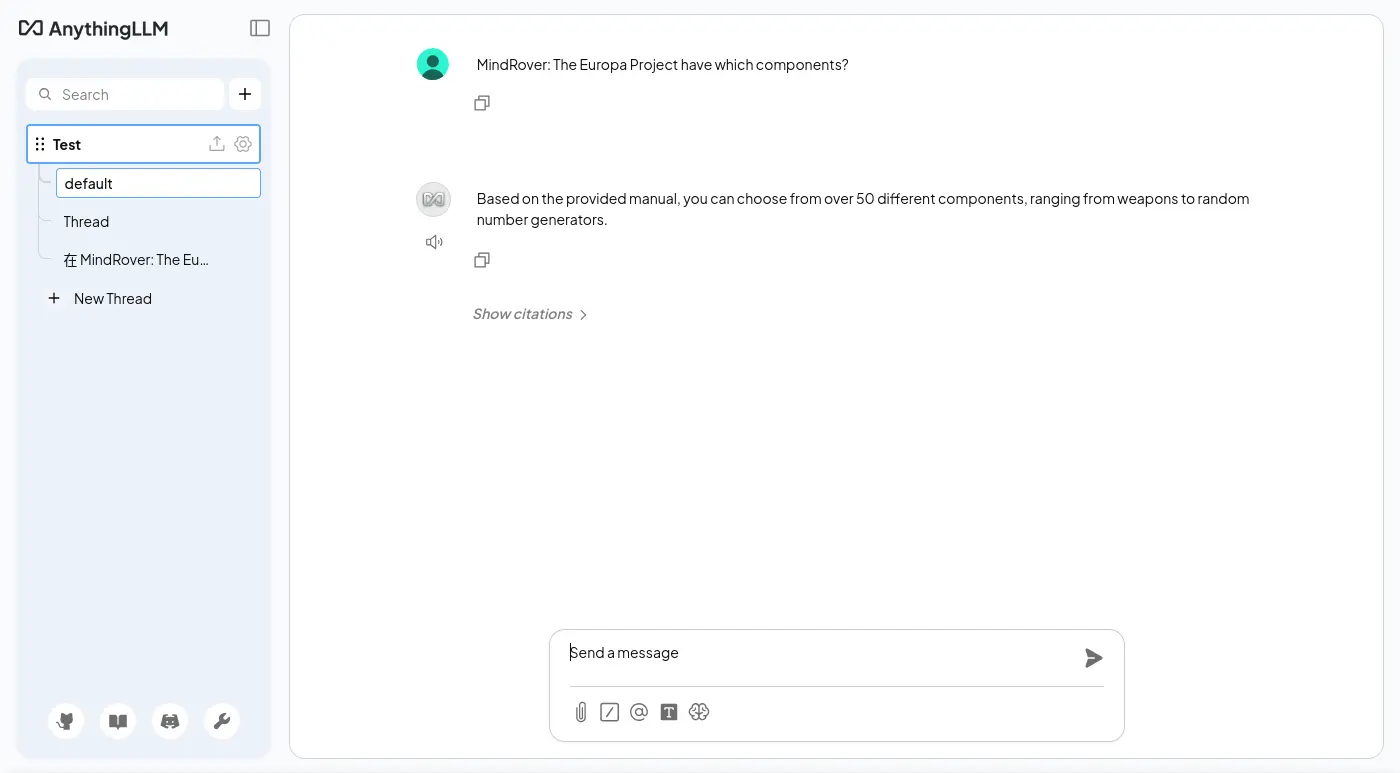
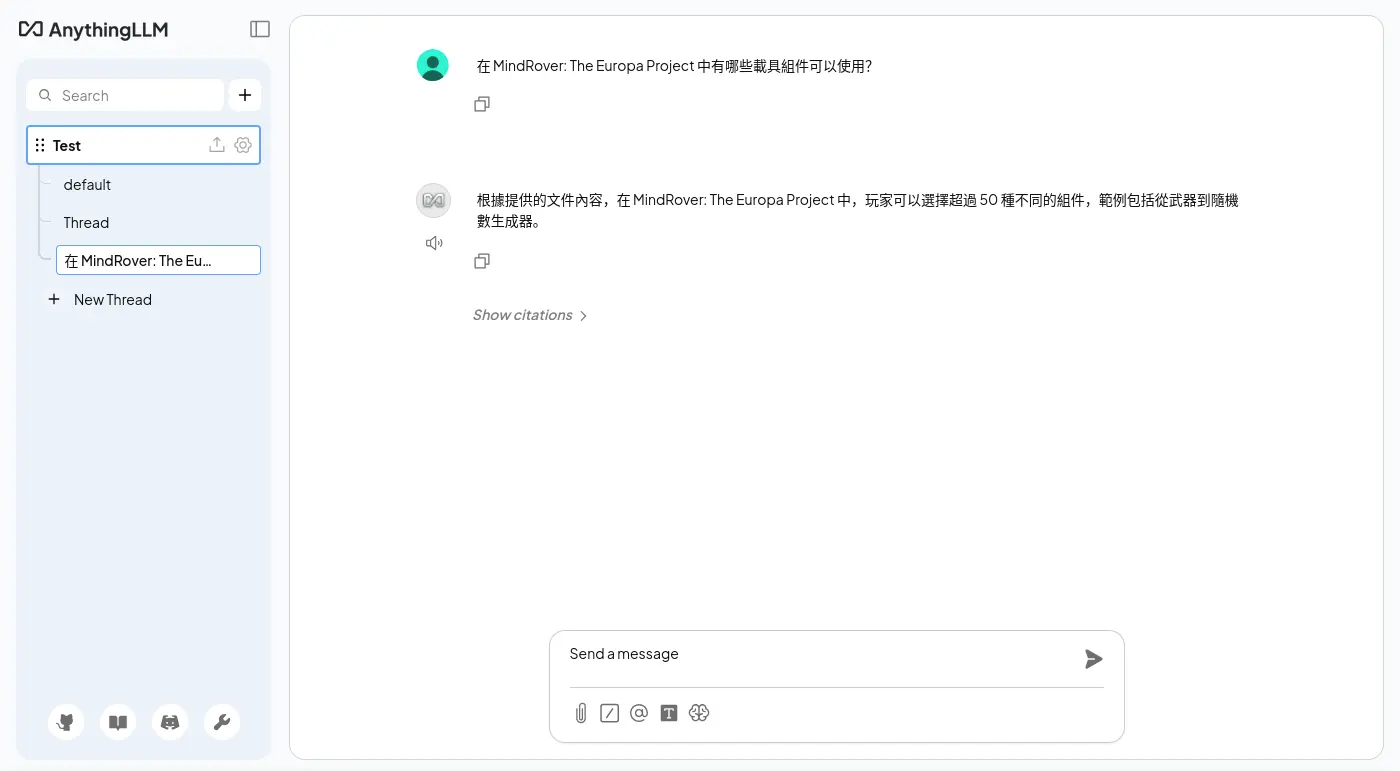
透過 Attu 就能瀏覽 Milvus 內儲存的資料了:
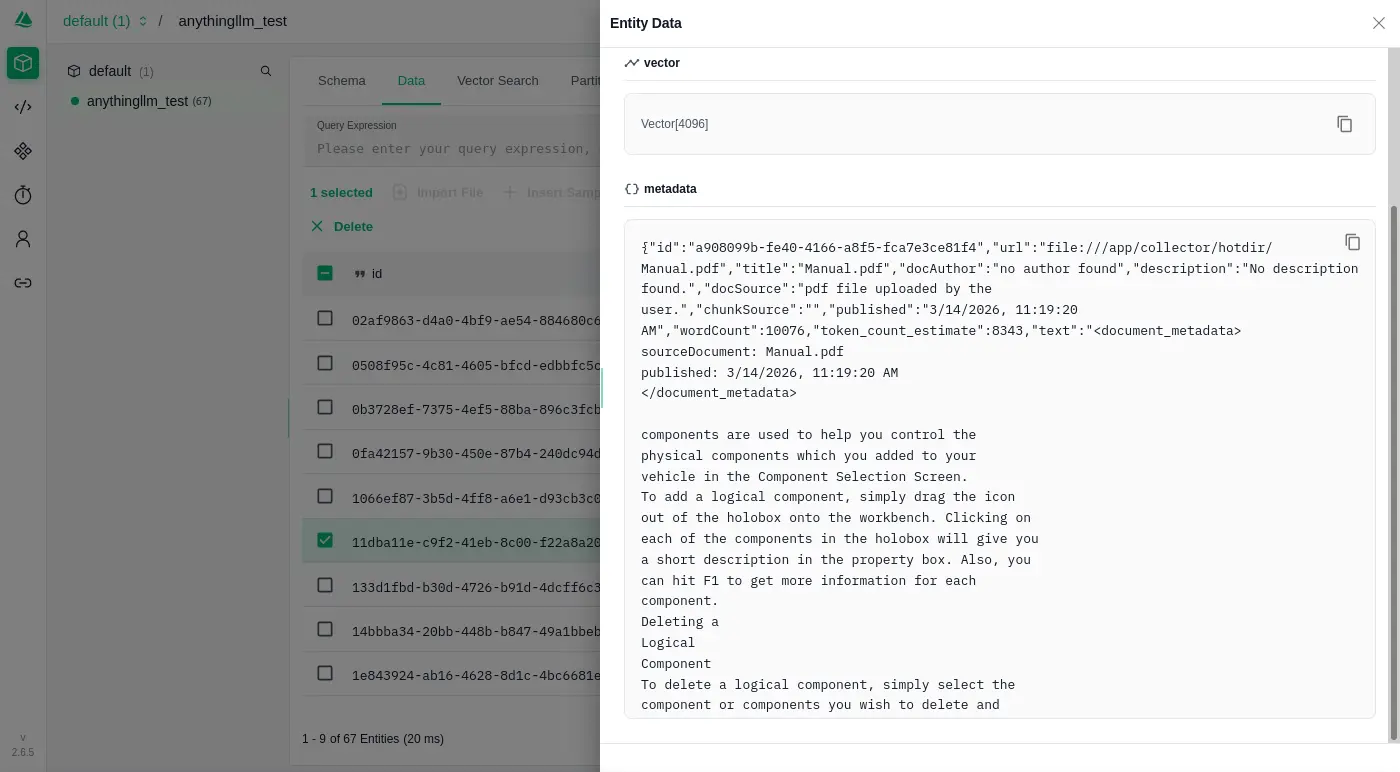
可以發現 AnythingLLM 是直接嵌入一個 JSON 資料:
實作程序關閉
是否有實作 Graceful Shutdown? 否。
如果程式有實作 Graceful Shutdown,它會監聽 SIGTERM 訊號,並且在收到後開始進入資源釋放流程;反之,如果沒有實做就會觀察到「下達容器關閉指令沒有反應,直到超時被服務強制中止」:
exit code: 137
WARN[0010] StopSignal SIGTERM failed to stop container anythingllm_anythingllm_1 in 10 seconds, resorting to SIGKILL
雜談
本來標題是想起個「評測」之類的,只是感覺這代表覆蓋的面向要足夠多,還要有可以量化的指標 (benchmark) 之類的,但是我只是想根據自己自己的需求「簡單翻閱一下」。
加上我在意的面向通常也不是一般使用者會在意的部份,如果看到「OOXX 評測」開開心心的點進來文章卻發現跟想像的不一樣這樣失望的話,那會有一點對不起讀者,所以最後給了一個「不正經」的標題,畢竟以一般 LLM 使用者的角度,我調查的點的確蠻不正經的。
另外,評測應該要給個總結,不過我這邊先不這樣做,因為沒有其他參照對象,也不知道 AnythingLLM 的表現是好是壞,大概等我手邊累積多一點資訊才會對各個應用程式做評分之類的總結。